
In His Shoes - Using Sequence Models To Generate Sentence Forecasts
Autocomplete features in messaging applications and search boxes on websites are common examples of systems that utilise sentence forecasting. The underlying assumption in these models is that it is possible to predict the next word in a sequence of words using some form of context such as the preceding sequence of words, browsing history, and time of day.
In this post I explore a simple approach of building a sentence forecasting model using preceding words as input data. I train using recurrent neural networks (RNNs), specifically networks that utilise long short-term memory (LSTM) models.
I take inspiration and code from a few blog posts from Jason Brownlee and Will Koehrsen, so credit to these guys.
I also do not go into the theory behind these models but for more information on the fundamentals of neural networks, I encourage you to check out a previous blog post I have written. For some material on RNNs and LSTMs I can recommend a couple of well-written posts here.
Data Collection
My initial aim for this project was to be able to build models that could replicate text from a wide variety of content, with the aim of being able to compare the writing styles from different publications (BBC vs. Daily Mail), different books (Alice in Wonderland vs. Doors of Perception), and Tweets from different people (Trump vs. Elon Musk). However, I was limited by the amount of time I was able to spend training models and so I focussed on using this open dataset on BBC articles.
This dataset gives article text split from different sections of their website and I thought these sections would give enough variation to expose the different themes that the model learns.
Data Preparation
Tokenising and Word<>Index Mappings
To convert this raw text data into a format I am able to train a model on, I first convert the raw text documents
into
an array of integers using the Tokenizer
object from Keras module from TensorFlow. This does several useful things for us: 1. It
performs some string processing (concerting all text to lowercase and filtering some non alpha-numeric characters),
2. it builds a word to index lookups, and 3. applies the word to index lookup on the string data. This results in us
having a sequence of integers
represent the input strings and with these we can begin to form a training / validation set.
# Train Tokenizer and Apply
from tensorflow.keras.preprocessing.text import Tokenizer
# Train
tokenizer = Tokenizer()
tokenizer.fit_on_texts(text)
# Apply Tokenzier on Documents (convert words to numbers)
sequences = tokenizer.texts_to_sequences(text)
word_idx = tokenizer.word_index
num_words = len(word_idx) + 1
Sliding Windows
At this point, I pass a sliding window across sentences and extract sequences of words to generate training examples. The sliding window method, in this case, works by iterating through a fixed length, n, of words through input text and extracting the first (n-1) words as a feature, and the final nth word as the label. In a document with N words, this produces a total of (N - n + 1) samples of data to train on.
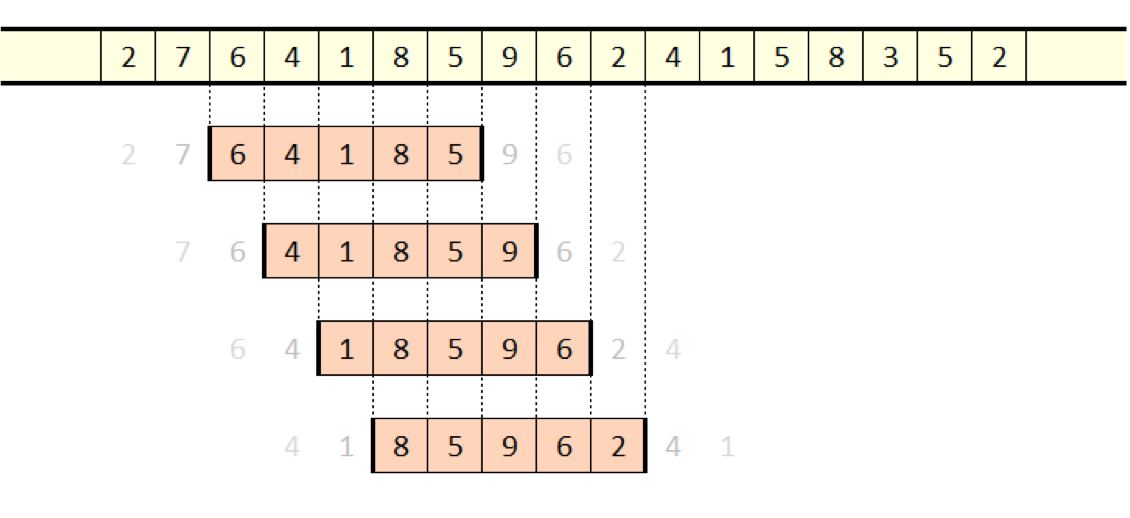
Sliding window
# Create Sliding Window
sequence_len = 10
features = []
labels = []
for sequence in sequences:
for i in range(len(sequence) - sequence_len):
window = sequence[i:sequence_len + i + 1]
features.append(window[:-1])
labels.append(window[-1])
print(f'There are {len(features)} sequences.')
Word Embeddings
When I build my model, I know that I want to the input layer of the network to be an Embedding layer.
Word embeddings are a way for us to represent words as vectors, where the relationship between words can be, in some
way, described by the relationship between their vectors. There are two commonly used word embeddings, GloVe and Word2Vec, and these have typically been trained on a
large corpus of text like (think Wikipedia or Common Crawl) and they provide
an n-dimensional vector for a given word. Basic arithmetic operations between these vectors can describe some real
world relationship between corresponding words.
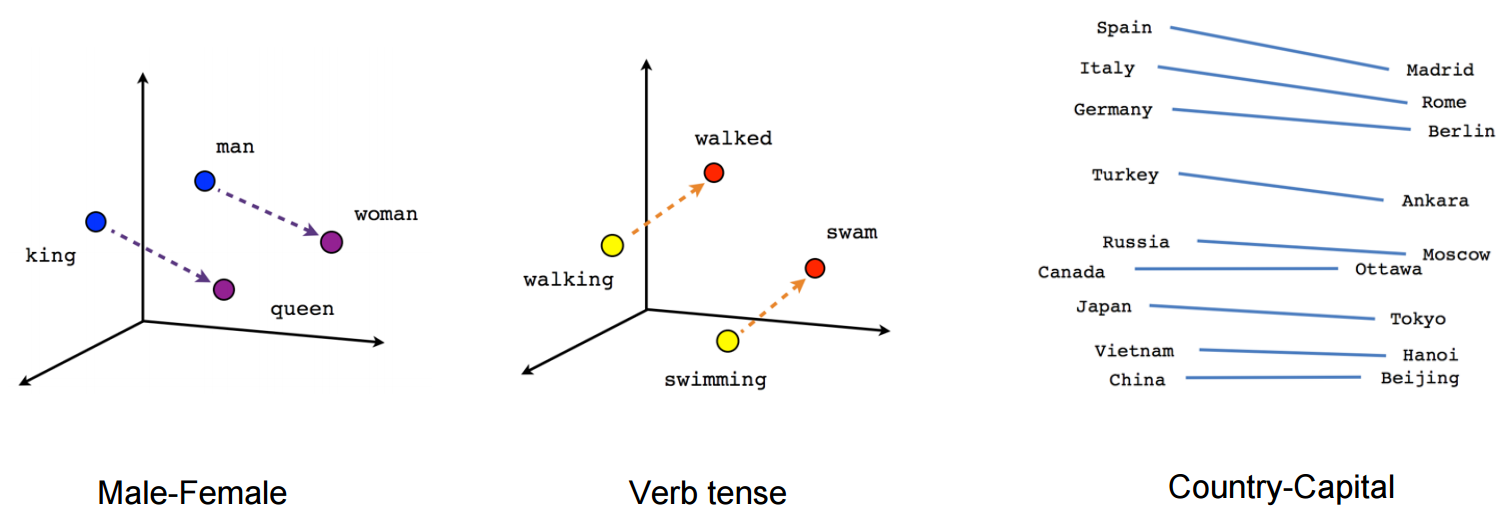
Word embeddings
To use the embeddings within the network, the vectors are reordered so it is aligned with word indexes that we will
feed the network with. This embedding matrix is used to initialise the Embedding layer.
glove_vectors = np.loadtxt(glove_vector_filepath, dtype='str', comments=None)
vectors = glove_vectors[:, 1:].astype('float')
words = glove_vectors[:, 0]
print('Glove Vectors loading with dimension {}'.format(vectors.shape[1]))
word_lookup = {word: vector for word, vector in zip(words, vectors)}
# Create Empty Index
embedding_matrix = np.zeros((num_words, vectors.shape[1]))
# Fill Index with Embedings
not_found = 0
for i, word in enumerate(word_idx.keys()):
# Look up the word embedding
vector = word_lookup.get(word, None)
# Record in matrix
if vector is not None:
embedding_matrix[i + 1, :] = vector
else:
not_found += 1
print(f'There were {not_found} words without pre-trained embeddings.')
# Normalize and convert nan to 0
embedding_matrix = embedding_matrix / np.linalg.norm(embedding_matrix, axis=1).reshape((-1, 1))
embedding_matrix = np.nan_to_num(embedding_matrix)
Model Design, Training and Evaluation
I build the network using the Keras Sequential API from
TensorFlow 2. This quickly lets me initialise a network, add a variety of layers, define an optimiser, and train the
model efficiently.
When training the model, I take advantage of EarlyStopping
which automatically interrupts the training process if some monitored metric does not improve after a few epochs. I
also use ModelCheckpoint
which saves the model during training so progress is not lost if the kernel crashes.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dropout, Dense
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# Define the model
model = Sequential()
model.add(
Embedding(
input_dim=num_words,
output_dim=embedding_matrix.shape[1],
weights=[embedding_matrix],
trainable=True)
)
model.add(LSTM(256, return_sequences=True, dropout=0.1, recurrent_dropout=0.1))
model.add(Dropout(0.2))
model.add(LSTM(256))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dense(num_words, activation='softmax')) # output layer
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model
callbacks = [
EarlyStopping(monitor='val_accuracy', patience=25),
ModelCheckpoint(f'{model_filepath}', save_best_only=True, save_weights_only=False, monitor='val_accuracy')
]
history = model.fit(
X_train,
y_train,
epochs=epochs,
batch_size=2048,
validation_data=(X_test, y_test),
verbose=1,
callbacks=callbacks
)

Example model summary
I train models using a cloud instance of a notebook in Google Colab as this allows me to train using a cloud GPU, which decreases training time from ~120 seconds to ~15 seconds per epoch, an 8x improvement when compared to training on my 2019 MacBook Pro 13" (1.4Ghz quad core i5, 8GB ram).
When using Google Colab, I ran into the problem of running out of RAM, and I discovered this was because of a few large variables that where not used and large Numpy matrices. The following code helped to solve this issue.
# Convert from float to int8 to reduce object size
from scipy.sparse import csr_matrix
labels = csr_matrix(labels).astype(np.int8)
labels = labels.toarray()
# Delete unused variables
import gc
gc.enable()
del labels
gc.collect()
Hyperparameter Tuning: Stage 1
To find the best model for each dataset, I perform a series of training and marginal model redesigns steps, and keeping parameters that optimise for validation accuracy. The results of the process when applied to the BBC Technology dataset is summarised in the tables below.
In this stage I change the following set of parameters:
- Input sequence length
- Number of LTSM layers
- Bidirectional final LSTM layer
- Trainable (updateable) embedding matrix
| LTSM Layers | Bidirectional | Trainable Embeddings | Sequence Length | Validation Loss | Validation Accuracy |
|---|---|---|---|---|---|
| 1 | False | False | 50 | 6.4511 | 0.1130 |
| 2 | False | False | 50 | 6.5666 | 0.1039 |
| 1 | True | False | 50 | 6.3906 | 0.1154 |
| 2 | True | False | 50 | 6.5250 | 0.1065 |
| 1 | False | True | 50 | 6.6767 | 0.1770 |
| 1 | True | True | 50 | 6.9115 | 0.1669 |
| 2 | True | True | 20 | 6.8365 | 0.1451 |
| 1 | False | True | 20 | 6.6482 | 0.1757 |
Hyperparameter Tuning: Stage 2
I noticed that the train loss and train accuracy where consistently higher than validation Loss and validation accuracy, suggesting that the model was over fitting hence I tried to alter the dropout within the LSTM layer with the following results.
| LTSM Layers | Bidirectional | Trainable Embeddings | Sequence Length | LSTM Dropout | LSTM Recurrent Dropout | Validation Loss | Validation Accuracy |
|---|---|---|---|---|---|---|---|
| 1 | False | True | 50 | 0.1 | 0.1 | 6.5235 | 0.1715 |
| 1 | False | True | 50 | 0.2 | 0.2 | 6.4229 | 0.1706 |
| 1 | False | True | 50 | 0.5 | 0.5 | 6.2247 | 0.1638 |
| 1 | False | True | 20 | 0.1 | 0.1 | 6.4449 | 0.1725 |
| 1 | False | True | 20 | 0.2 | 0.2 | 6.2899 | 0.1706 |
| 1 | False | True | 20 | 0.5 | 0.5 | 6.1667 | 0.1719 |
Hyperparameter Tuning: Stage 3
I could not conclude that using dropouts within the LSTM layer had any affect, so I decided to redesign the model with multiple LSTM layers with dropout layers between them. I also had a go at changing the number of cells within each LSTM layer. The following results keep the embedding layer trainable and I reduce the sequence length to 10 words.
| LSTM Layers | LSTM Cells per Layer | Dropout % | Validation Loss | Validation Accuracy |
|---|---|---|---|---|
| 1 | 64 | 0.2 | 8.9918 | 0.2271 |
| 1 | 256 | 0.2 | 10.7950 | 0.2354 |
| 1 | 256 | 0.5 | 8.9682 | 0.2153 |
| 2 | 64 | 0.2, 0.5 | 6.9549 | 0.1490 |
| 2 | 256 | 0.2, 0.5 | 7.4581 | 0.1683 |
| 2 | 256 | 0.5, 0.5 | 7.3286 | 0.1650 |
Results after 100 epochs
| LSTM Layers | LSTM Cells per Layer | Dropout % | Validation Loss | Validation Accuracy |
|---|---|---|---|---|
| 1 | 64 | 0.2 | 16.4351 | 0.3229 |
| 1 | 256 | 0.2 | 22.5922 | 0.3373 |
| 1 | 256 | 0.5 | 18.8511 | 0.3329 |
| 2 | 64 | 0.2, 0.5 | 8.8127 | 0.2230 |
| 2 | 256 | 0.2, 0.5 | 10.8240 | 0.2854 |
| 2 | 256 | 0.5, 0.5 | 10.4388 | 0.2666 |
Results after 500 epochs

Training history
Final Model Results and Baseline Comparison
To get a baseline metric to benchmark the trained networks, I came up with a few simpler approaches in predicting following words. One approach is to randomly guess the following word, and the other set of approaches is to build a mapping between every n-gram and predicting the most frequent word after n-gram. The numbers in the table below are the accuracy scores on a validation set where the most-frequent n-gram model is labelled as 'Conditional Guess' and the LSTM column refers to the best model I found trained to convergence.
| Dataset | Random Guess | Conditional Guess (n=1) | Conditional Guess (n=2) | Conditional Guess (n=3) | LSTM |
|---|---|---|---|---|---|
| BBC Technology | 0.01 | 0.10 | 0.23 | 0.29 | 0.38 |
| BBC Politics | 0.001 | 0.09 | 0.16 | 0.17 | 0.19 |
| BBC Business | 0.001 | 0.08 | 0.11 | 0.09 | 0.15 |
Conclusion
Interpreting the results, our models are generally able to correctly predict the following 1/5-1/3 of the time. For a model trained with a few hours on a fairly small dataset and limited tuning, this is already better than my human-level performance.
Sample Output
The following quotes are some examples of input text data fed into the model, sequences generated by the best performing model, and the actual following sequences.
BBC Tech
and the current generation of mobiles using flash technology can store data for phones but some readers of the file sharing and both yahoo and bt in europe in the
and the current generation of mobiles using flash technology canstore up to one gigabyte of music enough for 250 songs we are working in the hard disk area and
cut between 6 000 and 7 000 jobs and reduce costs up from looking for to a international based development in california said iptv was scrapped in japan in 1976
cut between 6 000 and 7 000 jobs and reduce costs by 5bn £2 7bn a year analysts had warned recently that the airline might have to seek chapter 11
BBC Politics
the new year in the meantime we will be studying the announcement on his spending plans on the same after a meeting on labour's media media lord woolf for labour's
the new year in the meantime we will be studyingthe judgment carefully to see whether it is possible to modify our legislation to address the concerns raised by the
executive faces more than 1 000 similar claims for damages from their final crisis with senior police officers and more with half their people across custody and then in many
executive faces more than 1 000 similar claims for damages law firm tods murray where he is a partner mr mcletchie said he has taken advice from holyrood officials about
BBC Business
retirement under 65 employers will no longer be able to advise for the companies said mr rubinsohn is due to delivering improvements and the us's biggest manufacturers could be above
retirement under 65 employers will no longer be able toforce workers to retire before 65 unless they can justify it the government has announced that firms will be barred
surging and there are many companies who will continue with forecasts by 90 of its known manufacturing making currently frozen goods the firm recently indicated that the merger for an
surging and there are many companies who will continue withexisting trading relationships christian aid has called on british firms not to simply cut and run but look after their